EntityListeners를 이용한 엔티티 변경 로그 수집
개요
상황
- 저희 서비스는 데이터 수집을 위해 특정 엔티티의 변경 이력을 로그 테이블에 저장하고 있습니다.
- 기존에는 ‘로그 수집 로직’을 모든 ‘엔티티 변경 로직’에 붙이는 방식으로 처리하고 있었습니다.
- 그러나 이 방식은 엔티티 변경 로직이 변경 혹은 추가될 경우 로그 수집 로직을 명시적으로 작성하지 않으면 로그가 누락될 수 있는 문제가 있었습니다.
해결
- 1차 개선
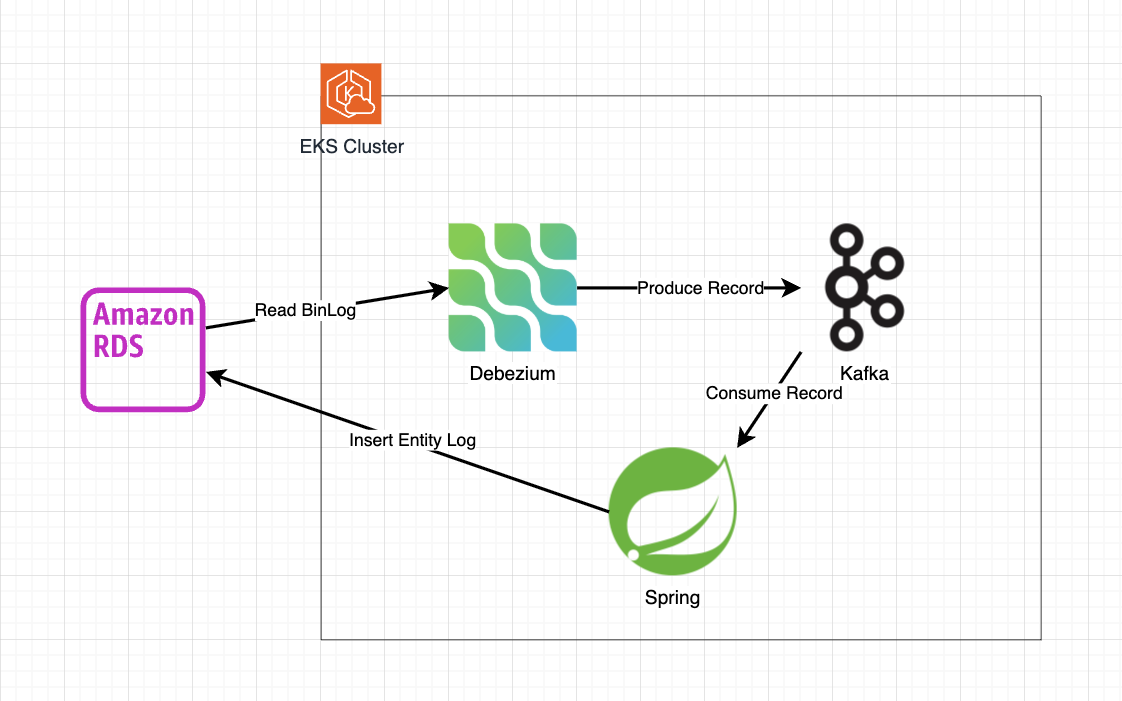
- EKS 클러스터에 Kafka와 Debezium으로 CDC를 구축하여 엔티티 변경 사항을 수집하고,
- Spring 서버에 Kafka Consumer를 구현하여 수집된 변경 내역을 로그 테이블에 자동으로 저장하도록 개선했습니다.
- 2차 개선(25.11)
- Bulk update를 각 Jpa 엔티티 단위로 수행하도록 로직을 분리 후
- @EntityListeners을 사용하여 자동으로 관리되도록 변경했습니다.
- 그 후 스트랭글러 패턴으로 점진적으로 CDC 구현을 제거했습니다.
결과
- 엔티티 변경 로직과 로그 수집 로직을 분리할 수 있게 되었습니다.
배경
저희 회사는 프리랜서 매칭 플랫폼을 운영하고 있습니다. 비즈니스의 특성상 업무 관련 수락, 거절, 업무 조건 수정 등 엔티티 변경이 빈번하게 발생합니다. 이러한 변경은 사용자 경험을 개선하기 위한 중요한 데이터이므로 변경 시마다 명시적으로 변경 내역을 RDB의 로그테이블에 동기 방식으로 저장하고 있었습니다. 그러나 위와 같은 방식은 아래의 문제점을 가지고 있습니다.
- 모든 엔티티 변경 로직 (CQRS 기준으로 Command에 해당)에 로그 수집 로직을 붙여야 하므로 누락될 가능성이 있습니다.
- *이미 누락된 case가 발견된 상황이었습니다.
비즈니스 개선을 위해 짧은 개발 시간 내에 누락 없이 완벽하게 모든 로그를 수집해야 하는 상황이었습니다.
2번에 걸친 개선 과정을 통해 모든 로그를 수집할 수 있게 되었습니다.
1차 개선 : Kafka & Debezium, CDC
Kafka & Debezium, CDC를 선택한 이유
Kafka & Debezium을 포함하여 아래의 방안을 고려했습니다. 각 방안의 장단점, 결론은 아래와 같습니다.
(참고사항 : 현재 운영 기준으로 EKS 클러스터에서 복수의 Spring Server를 운영하고 있습니다.)
1)이벤트 기반 아키텍쳐로 리팩토링 (기각)
- 가장 이상적인 방법일 수 있지만 촉박한 개발 일정 내에 적용이 불가능한 상황이므로 기각했습니다.
Envers (기각)
- 장점
- JPA와 손쉽게 통합 가능하다
- 단점
- Querydsl, JPQL의 bulk update/delete 쿼리는 추적 불가능하다
- 동기 방식으로 작동하므로 대량 데이터 처리 시 부하가 발생할 수 있다.
- 결론
- bulk update/delete 쿼리를 추적할 수 없는 것과 성능 이슈가 치명적인 단점이라 판단하여 채택하지 않았습니다.
Debezium Engine을 이용한 CDC 구축 (기각)
- 장점
- Kafka 없이 CDC 구현 가능하므로 인프라를 간소화 할 수 있다
- 비즈니스 로직과 로그 수집 로직을 분리할 수 있다
- 단점
- Debezium Engine만을 위한 단독 서버를 구축해야 한다
- 결론
- Debezium Engine만을 위한 단독 서버를 구축해야 하는 점이 큰 단점이라 판단했습니다. 이유는 아래와 같습니다.
- 기존 Spring 서버와 별개의 git repository를 구축해야 하므로 개발팀 구성원이 변경되는 등의 이유로 Debezium Engine 서버가 잊혀질(?) 경우 버그가 발생할 가능성이 높으며
- 추후 트래픽이 증가했을 때 Debezium Engine은 고가용성을 보장하기 어려움
- Debezium Engine만을 위한 단독 서버를 구축해야 하는 점이 큰 단점이라 판단했습니다. 이유는 아래와 같습니다.
Kafka & Debezium을 이용한 CDC 구축 (선택)
- 장점
- 풍부한 레퍼런스
- 높은 처리량, 고가용성 보장
- Kafka 컨슈머 그룹의 특성을 이용하여 ElasticSearch 등 다양한 Source로 확장할 수 있다
- 단점
- 현재 당장의 트래픽으로는 고가용성이 필요하지 않음
- 인프라 구축 복잡도 증가 및 추가 운영 비용 발생
- 결론
- 아래의 이유로 단점이 보완될 수 있다고 판단했습니다
- 현재 EKS를 사용하고 있으며 Worker Node의 리소스가 남는 상황임
- 따라서 EKS에 Kafka & Debezium를 구축한다면 초기 세팅 이후에는 쿠버네티스 특성 상 명시적이고 자동화된 관리를 기대할 수 있어 인프라 운영 난이도가 낮으며 추가 비용도 적게 발생할 것
- 추후 다양한 용도로 활용 가능 (추천 시스템 고도화, 캐시 갱신 등 )
- 추후 트래픽이 증가했을 때 손쉽게 scale-out 가능
- 현재 EKS를 사용하고 있으며 Worker Node의 리소스가 남는 상황임
- 아래의 이유로 단점이 보완될 수 있다고 판단했습니다
위의 이유로 Kafka & Debezium을 이용하여 CDC를 적용하기로 결론지었습니다.
Kafka 세팅
인프라 비용 절감을 위해 아래 방식으로 Kafka를 사용했습니다.
- Kraft 모드 사용
- Zookeeper를 사용하지 않으므로 인스턴스 비용 절감이 가능합니다.
- 브로커, 파티션을 1개씩만 설정
- 고가용성이 보장되지 않으므로 일반적으로 개발환경 외에는 사용되지 않는 방식입니다.
- 단 현재 서비스 상황 상 트래픽이 많지 않아 장애 우려가 적으며 필요할 경우 빠르게 scale-out 하면 된다고 판단했습니다. 대신 후술할 별도의 모니터링을 통해 장애가 발생할 경우 빠르게 대응할 수 있도록 대비했습니다.
명시적이고 자동화된 관리를 위해 AWS EKS에 Debezium과 Kafka를 설치했습니다.
Retry & DLQ
데이터베이스에 장애가 발생하거나 데이터베이스의 스키마 변경이 어플리케이션 로직에 반영되지 않는 등 다양한 이유로 특정 Record를 Consume 하는 시점에 예외가 발생할 수 있습니다. 이 때 Consume을 계속 시도할 경우 정상처리가 가능한 Record도 대기해야 하는 문제가 발생합니다.
이 문제를 방지하기 위해 특정 횟수만큼 Retry를 시도하고 그 이후에는 Dead Letter Queue에 Produce하는 방식으로 처리했습니다.
아래는 ‘Ticket’ 이라는 엔티티의 변경 내역을 ‘TicketLog’라는 테이블에 저장하는 로직이 있다고 가정한 예시입니다.
여담으로 굳이 레코드를 Ticket 엔티티로 변환 후 TicketLog으로 변환하였습니다. 이는 추후 Ticket 엔티티를 변경할 때 TicketLog의 fromEntity 메소드도 변경이 필요한 것을 컴파일 단계에서 자연스럽게 알 수 있게 하기 위함입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@KafkaListener(topics = TICKET_LOG_TOPIC_NAME, groupId = TICKET_LOG_GROUP_ID)
public void listen(ConsumerRecord<String, String> record, Acknowledgment ack) {
int maxRetries = 3;
int attempt = 0;
while (attempt < maxRetries) {
try {
//1. 로그 테이블에 변경내역 저장
Ticket ticket = mapToTicket(record.value());
TicketLog ticketLog = TicketLog.fromEntity(ticket);
saveTicketLog(ticketLog);
break;
} catch (Exception e) {
//2. 예외 발생 시 재시도 로직
attempt++;
log.error("Error processing message (attempt " + attempt + "): " + e.getMessage());
//3. 재시도 횟수가 최대에 도달하면 DLQ로 전송
if (attempt >= maxRetries) {
sendToDLQ(record);
}
}
}
ack.acknowledge(); // 4. 수동으로 ack 처리
}
Binlog의 file, position 을 uniqe value로 사용하여 멱등성 보완
- 문제
- 공식문서에 따르면 debezium은 정상 상황에서 exactly-once를 보장하나 장애 시에는 at-least-once를 보장합니다. 때문에 장애 시 엔티티 변경 이력이 중복 저장될 수 있습니다.
- 해결
- 이를 보완하기 위해 로그 테이블에 binlog의 file, position도 같이 저장하여 중복 데이터를 구분할 수 있도록 하였습니다.
- MySQL의 특성 상 binlog 동일 file 기준으로 position는 unique합니다.
- 따라서 만약 중복이 발생했을 경우 file 및 position을 기준으로 중복 데이터를 추출 및 삭제할 수 있습니다.
데이터 예시
PK 유니크 값({file}:{position}) type 엔티티 필드1 엔티티 필드2 1 mysql-bin-changelog.231401:10042 UPDATE BLAH BLAH BLAH BLAH 2 mysql-bin-changelog.362209:20087 INSERT BLAH BLAH BLAH BLAH
- 이를 보완하기 위해 로그 테이블에 binlog의 file, position도 같이 저장하여 중복 데이터를 구분할 수 있도록 하였습니다.
- UNIQUE 제약조건을 사용하여 멱등성을 보장하지 않은 이유
- MySQL의 UNIQUE 제약조건을 부여할 경우 로그을 저장하는 시점에 중복 여부를 검증할 수 있습니다.
- 하지만 UNIQUE 제약조건은 별도로 INDEX를 생성하는 것이므로 관리하는데 비용이 발생합니다.
- 따라서 중복이 발생하더라도 file, position을 이용하여 후처리하는 것이 바람직하다고 판단하여 퍼포먼스 및 비용절감을 위해 UNIQUE 제약조건을 사용하지 않았습니다.
- MySQL의 UNIQUE 제약조건을 부여할 경우 로그을 저장하는 시점에 중복 여부를 검증할 수 있습니다.
타임스탬프를 이용한 순서보장 보완
- 문제
- 공식문서에 따르면 Debezium은 순서를 보장합니다.
- 다만 카프카의 특성 상 동일 토픽 기준으로 여러 파티션을 사용할 경우 순서가 보장되지 않습니다.
- 해결
- 별도의 로직으로 직접 순서보장을 하기 보다는 필요할 경우 순서 기준으로 정렬이 가능하도록 변경 시점의 timestamp를 저장하도록 구현했습니다.
데이터 예시
PK 유니크 값({file}:{position}) type timestamp 엔티티 필드1 1 mysql-bin-changelog.231401:10042 UPDATE 1754889144364 BLAH BLAH 2 mysql-bin-changelog.362209:20087 INSERT 1754889371681 BLAH BLAH
모니터링
Spring Scheduler를 이용하여 주기적으로 Consumer Lag를 모니터링 하고 특정 수치 이상일 경우 슬랙으로 알림을 받아볼 수 있도록 구현했습니다.
DLQ 로직에 문제가 있거나 Consumer의 처리 속도가 Producer에 비해 느릴 경우 Consumer Lag이 발생할 수 있기 때문입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public List<Long> getConsumerLagList(String groupId) throws ExecutionException, InterruptedException {
// 1. 컨슈머 그룹의 파티션 별 오프셋 조회
Map<TopicPartition, OffsetAndMetadata> offsets =
adminClient.listConsumerGroupOffsets(groupId)
.partitionsToOffsetAndMetadata().get();
// 2. logEndOffset 조회
Map<TopicPartition, OffsetSpec> requestLatestOffsets = new HashMap<>();
for (TopicPartition tp : offsets.keySet()) {
requestLatestOffsets.put(tp, OffsetSpec.latest());
}
Map<TopicPartition, ListOffsetsResult.ListOffsetsResultInfo> endOffsets =
adminClient.listOffsets(requestLatestOffsets).all().get();
// 3. 각 파티션의 lag 계산 및 수집
List<Long> lagList = new ArrayList<>();
for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) {
TopicPartition tp = entry.getKey();
long currentOffset = entry.getValue().offset();
long logEndOffset = endOffsets.get(tp).offset();
long lag = logEndOffset - currentOffset;
lagList.add(lag);
}
return lagList;
}
2차 개선 : @EntityListeners 적용
Kafka & Debezium을 이용하여 급한 불은 껐습니다. 그러나 해당 구현 방식은 서비스의 규모 대비 오버엔지니어링이라고 판단되어 계속 고민했습니다. 그 결과 @EntityListeners 를 이용하여 엔티티 변경 로직과 로그 수집 로직을 분리하기로 결정했습니다.
@EntityListeners를 선택한 이유
아래의 근거를 이유로 Envers 대신 @EntityListeners를 선택했습니다.
Envers
- 장점 : 별도 코드 없이 @Audited만 선언하면 변경 이력 자동 기록이 가능
- 단점 : _AUD 테이블 구조가 고정돼 있고, 커스터마이징이 어렵다
@EntityListeners
자유롭게 커스텀이 가능하며 필요할 경우 Kafka 등의 메시지 큐와 결합하여 확장 용이
구현 상세
1)기존 bulk query를 JPA 엔티티 마다 실행되도록 로직 분리
현재 서비스의 상황 상 TPS가 크지 않으므로 동기 방식으로 구현해도 성능 이슈가 없다고 판단했습니다. 따라서 JPA 변경감지를 활용하기 위해 기존 bulk update query를 개별 JPA 엔티티 마다 변경감지를 이용하는 방식으로 레거시 로직을 분리하는 절차를 진행했습니다.
2)@EntityListeners를 이용하여 로그 수집 로직을 단일 클래스에서 관리하도록 구현 아래 예시처럼 응집성을 위해 단일 클래스에서 모든 로그 수집을 담당하고 엔티티에는 어노테이션만 작성하면 되도록 구현했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Component
public class TicketEntityListener {
private final TicketLogRepository logRepository;
@Autowired
public void init(TicketLogRepository repository) {
logRepository = repository;
}
@PostPersist
public void afterCreate(Ticket ticket) {
saveLog(ticket, "CREATE");
}
@PostUpdate
public void afterUpdate(Ticket ticket) {
saveLog(ticket, "UPDATE");
}
@PostRemove
public void afterDelete(Ticket ticket) {
saveLog(ticket, "DELETE");
}
private void saveLog(Ticket ticket, String action) {
TicketLog log = TicketLog.fromEntity(ticket, action);
logRepository.save(log);
}
}
1
2
3
4
5
6
@EntityListeners(TicketEntityListener.class)
public class Ticket {
.
.
.
3)스트랭글러 패턴으로 점진적으로 CDC 구현 제거
아래 방식으로 스트랭글러 패턴을 사용하여 기존 CDC를 대체했습니다.
- 기존 CDC(Debezium) 파이프라인은 유지.
- 신규 EntityListener 기반 로그 수집을 일부 엔티티에 적용.
- 점진적으로 모든 CDC 파이프라인을 제거하면서 EntityListener로 전환.
결과
- 엔티티 변경 로직과 로그 수집 로직을 분리할 수 있게 되었습니다.
- 확장성을 가지면서도 JPA 엔티티를 중심으로 비즈니스 로직이 응집되는 효과를 얻었습니다.
참고자료
- Debezium 공식문서 : 장애 여부에 따른 Debezium의 exactly-once 및 at-least-once
- Debezium 공식문서 : Debezium의 순서보장 여부